tl;dr!: Computer vision models transfer poorly to unlabeled domains, and the current standard of addressing this using unsupervised domain adaptation lacks mechanism for incorporating text guidance. We propose a novel framework called LaGTrAn, which leverages natural language to guide the transfer of discriminative knowledge from labeled source to unlabeled target domains in image and video classification tasks. Despite its simplicity, LaGTrAn is highly effective on a variety of benchmarks including GeoNet and DomainNet. We also introduce a new benchmark called Ego2Exo to facilitate robustness studies across viewpoint variations in videos, and show LaGTrAn's effeciency in this novel transfer setting.
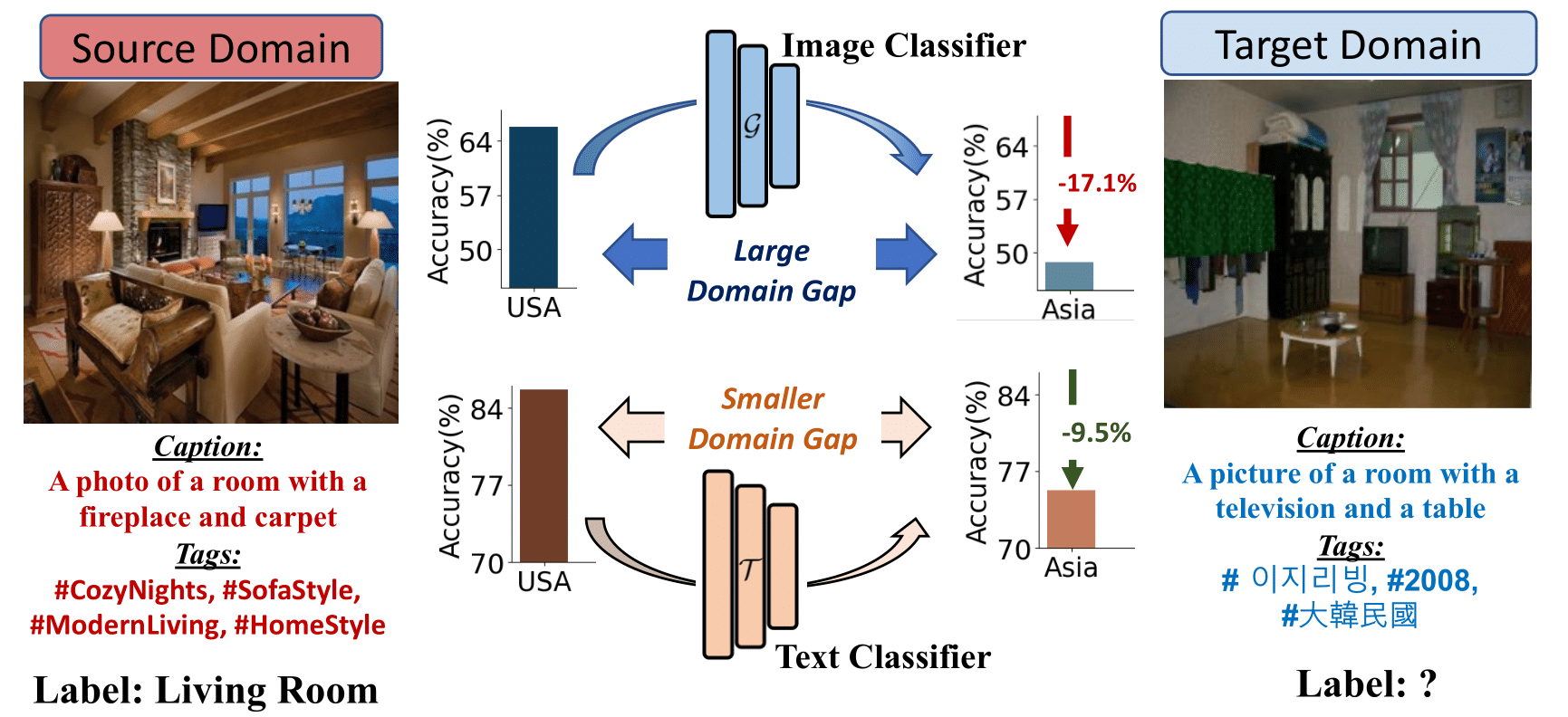
In a domain transfer setting with labeled source and unlabeled target domain data, transferring image classifier incurs significantly more cross-domain drop than text classifiers trained on corresponding captions. We leverage this insight to build a simple framework called LaGTrAn that uses text descriptions easily available in both domains to improve transfer in images and videos.
LaGTrAn for Language Guided Transfer
What is the problem setting? We operate in a setting where we have supervision from a source domain and no supervision from a different target domain. We are interested in transferring discriminative knowledge from the source domain to the target domain, to eventually improve the accuracy on the target domain. New to this setting, we assume access to readily available or easily producible language descriptions for each image in both source and target domains which greatly helps easing the transfer.
Don't UDA methods suffice in this setting? While UDA methods have been established to address this problem, they show limitations in handling challenging domain shifts due to their exclusive operation within the pixel-space. Motivated by our observation that semantically richer text modality has more favorable domain transfer properties, we devise a transfer mechanism to use a source-trained text-classifier to generate predictions on the target text descriptions and utilize these predictions as supervision for the corresponding images. As we show in our results, our LaGTrAn achieves better performance then any UDA method even without any complex adaptation procedure.
So what does LaGTrAn do differently? LaGTrAn proceeds by first training a BERT-classifier using source captions and labels. From our observations, this would yield more robust pseudo-labels compared to the common image-based transfer, eliminating the need for advanced refinement modules or curriculum training strategies. We then use this trained model to generate pseudo-labels for the target captions, which are then transferred to corresponding, unlabeled target domain images. Using this generated supervision along with source domain data, we jointly train a vision classifier towards image or video classification.
An overview of training using LaGTrAn
Why does LaGTrAn work? A key factor in the success of LaGTrAn is the rich semantic information in the text modality with comparitively reduced domain gaps that guides the transfer of discriminative knowledge from the source to the target domain. This is particularly effective in handling challenging domain shifts where characterizing and bridging domain gaps using images alone is difficult, as we show in our results.
Ego2Exo Benchmark for Cross-View Transfer in Videos
Get Kitchenware (ego -> exo)
Boil Noodles (ego -> exo)
Brew Coffee (ego -> exo)
Check Recipe (ego -> exo)
Make Chai Tea (ego -> exo)
Prepare Milk (exo -> ego)
Clean Up (exo -> ego)
What is Ego2Exo? We leverage the recently proposed Ego-Exo4D dataset to create a new benchmark called Ego2Exo to study ego-exo transfer in videos. Ego2Exo contains videos from both egocentric and exocentric viewpoints, and is designed to facilitate robustness studies across viewpoint variations in videos.
Why do we need Ego2Exo? It is fundamental to transfer knowledge learned from one view-point and apply it on variety of other viewpoints in videos. Despite rapid advances in methods and benchmarks for video domain adaptation, little insight is available into their ability to address this challenging setting between ego (first-person) and exo (third-person) perspectives in videos. Ego2Exo is designed as a new testbed to address this gap.
How is Ego2Exo created? We curate our dataset using the recently proposed Ego-Exo4D dataset, utilizing their keystep annotations for action labels, and atomic descriptions as text supervision. We map the keystep labels with the atomic narrations for each action segment using the provided timestamps, and manually remap the labels to ease the difficult task of predicting very fine-grained action classes from short segments (eg: add coffee beans vs. add coffee grounds). The complete details about our dataset creation process are included in our paper.
Where is Ego2Exo available? You should first download the videos from Ego-Exo4D benchmark following their guidelines. You can then download the json file containing the annotations and corresponding metadata for Ego2Exo from this link. More details about preparing the dataset for training and evaluation are included along with our code.
Results
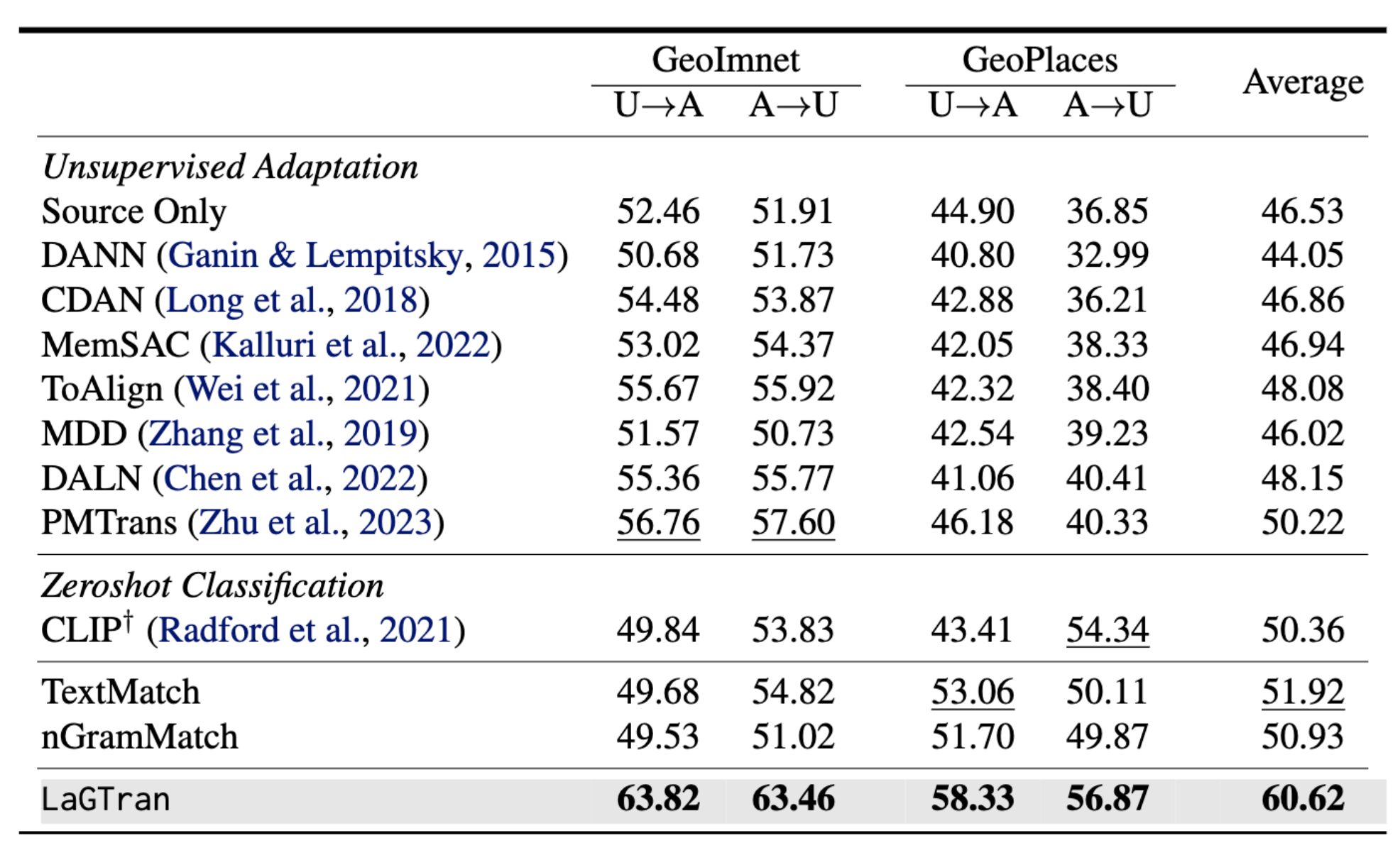
How does LaGTrAn compare with other UDA methods? We compare LaGTrAn with several UDA methods on the challenging GeoNet dataset. As shown below, LaGTrAn outperforms all UDA methods by a significant margin, indicating its effectiveness in handling challenging domain shifts.
LaGTrAn outperforms all UDA methods by a significant margin on the challenging GeoNet dataset.
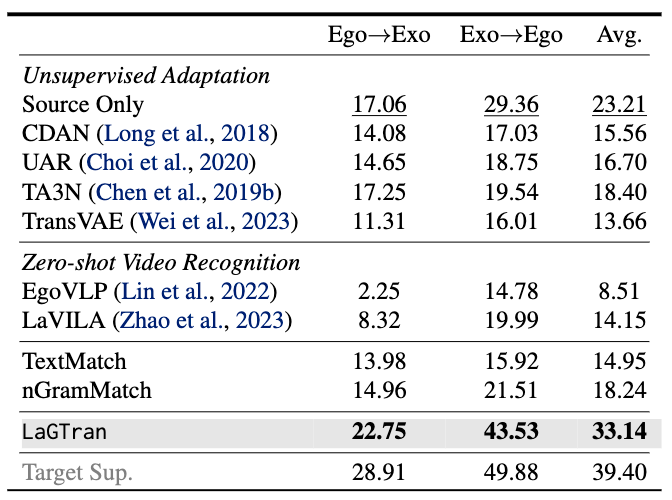
How well does LaGTrAn extend to videos? We evaluate LaGTrAn on the novel Ego2Exo benchmark and show that it yields significant gains in this novel transfer setting, validating the hypothesis that language offers a natural guidance for transfer across domains in videos.
LaGTrAn outperforms video-UDA as well as video-language based methods on the Ego2Exo benchmark.
Visualization of image vs text-based retrievals LaGTrAn retrieves more semantically similar images using text-based retrievals compared to image-based retrievals for a given source image, indicating the effectiveness of LaGTrAn in leveraging text guidance for transfer across domains.
BibTeX
@article{kalluri2024lagtran,
author = {Kalluri, Tarun and Majumder, Bodhisattwa and Chandraker, Manmohan},
title = {Tell, Don`t Show! Language Guidance Eases Transfer Across Domains in Images and Videos},
journal = {ICML},
year = {2024},
url = {https://arxiv.org/abs/2403.05535},
},