We present MemSAC for unsupervised domain adaptation across datasets with many categories or fine-grained classes.
Practical real world datasets with plentiful categories introduce additional challenges for unsupervised domain adaptation like small inter-class discriminability, that existing approaches relying only on domain invariance cannot handle sufficiently well. In this work we propose MEMory augmented SAmple Consistency (MemSAC), which exploits sample level similarity across source and target domains to achieve discriminative transfer, along with architectures that scale to a large number of categories. For this purpose, we first introduce a memory augmented approach to efficiently extract pairwise similarity relations between labeled source and unlabeled target domain instances, suited to handle an arbitrary number of classes. Next, we propose and theoretically justify a novel variant of the contrastive loss to promote local consistency among within-class cross domain samples while enforcing separation between classes, thus preserving discriminative transfer from source to target. We validate the advantages of MemSAC with significant improvements over previous state-of-the-art on multiple challenging transfer tasks designed for large-scale adaptation, such as DomainNet with 345 classes and fine-grained adaptation on Caltech-UCSD birds dataset with 200 classes.
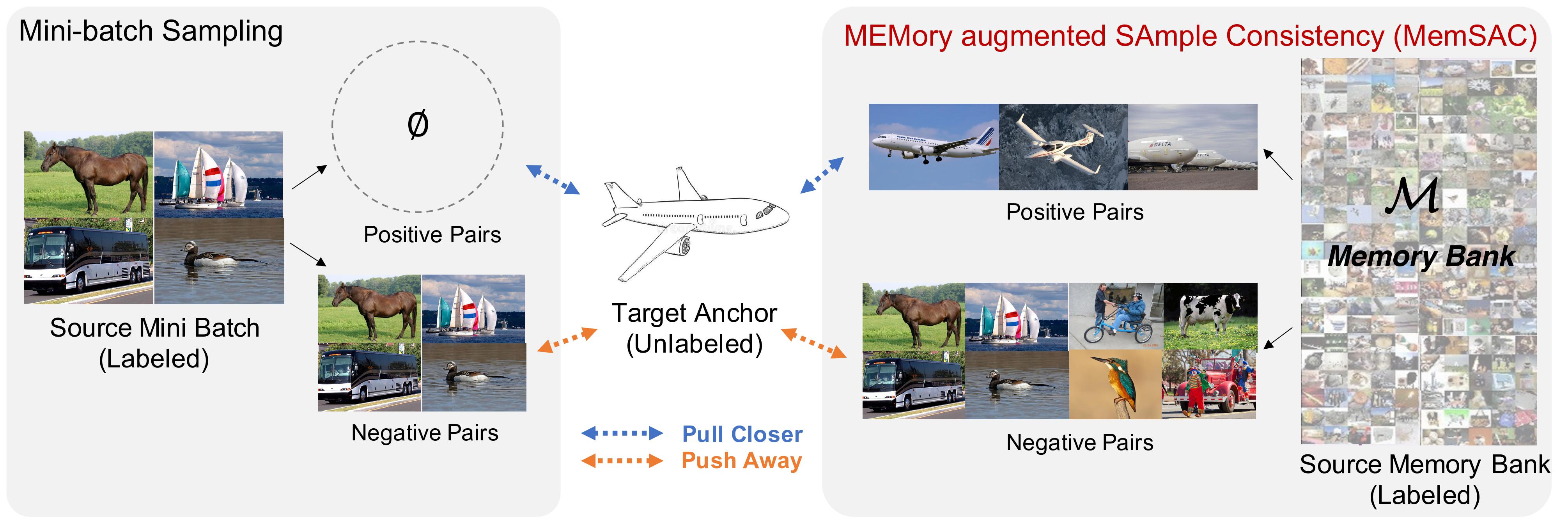
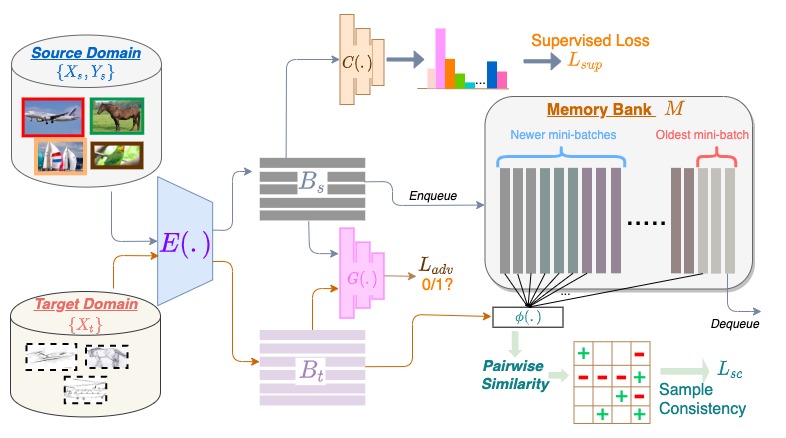
During each iteration, the 256-dim source feature embeddings computed using E, along with their labels, are added to a memory bank M and the oldest set of features are removed. Pairwise similarities between each target feature in mini-batch and all source features in memory bank are used to extract possible within-class and other-class source samples from the memory bank. Using the proposed consistency loss on these similar and dissimilar pairs, along with adversarial loss, we achieve both local alignment and global adaptation.
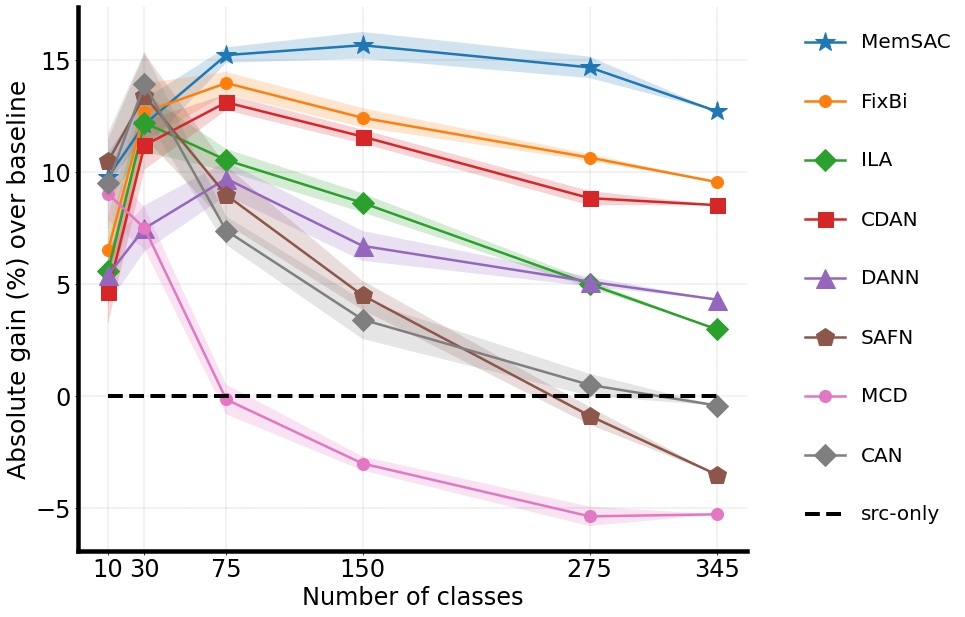
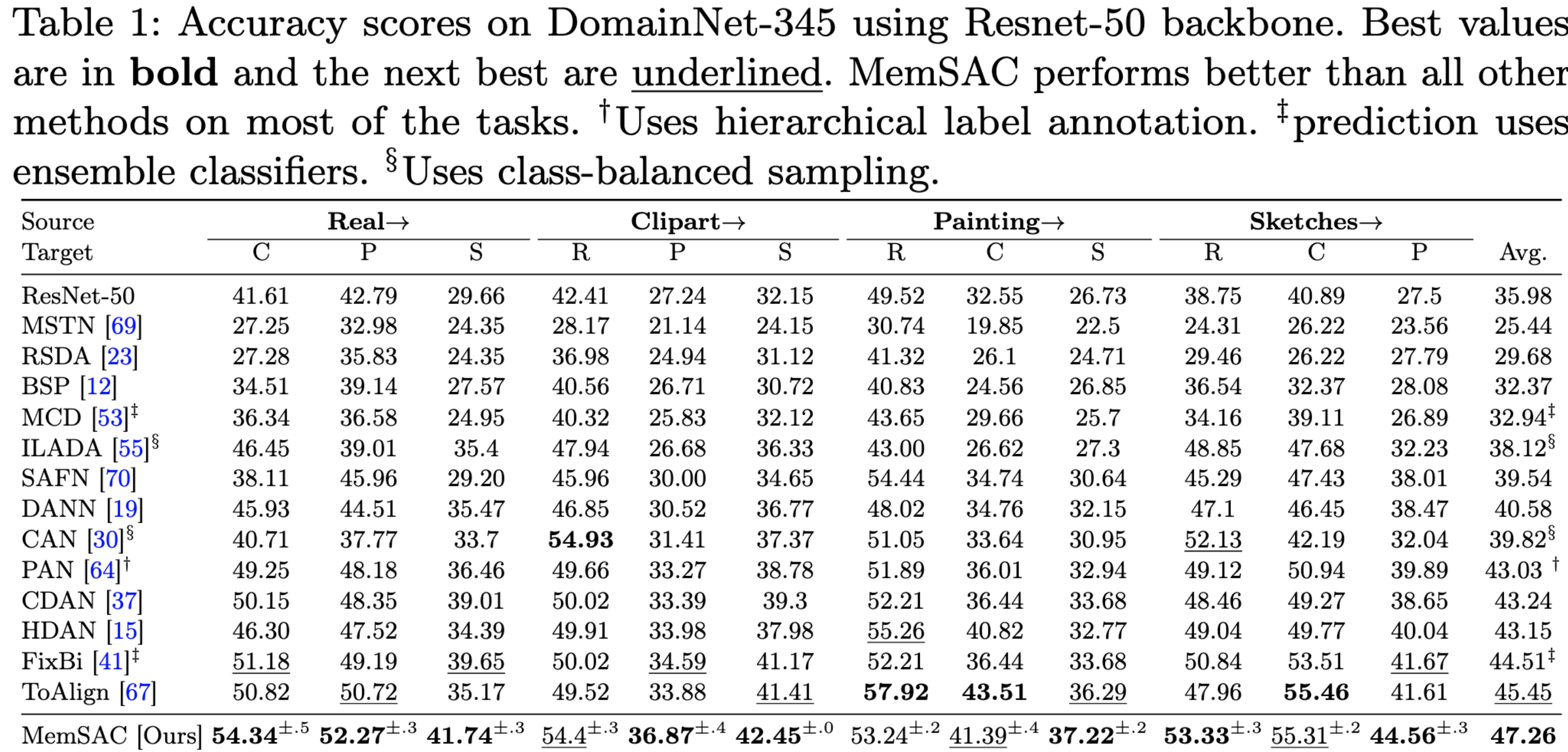
We achieve new SOTA on the challenging DomainNet dataset with 345 categories.
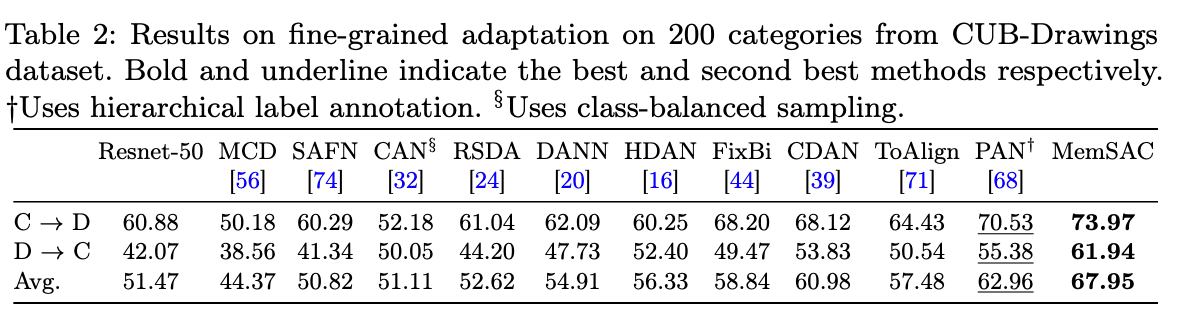
We achieve new SOTA on the fine-grained Caltech-UCSD dataset with 200 bird categories.
.
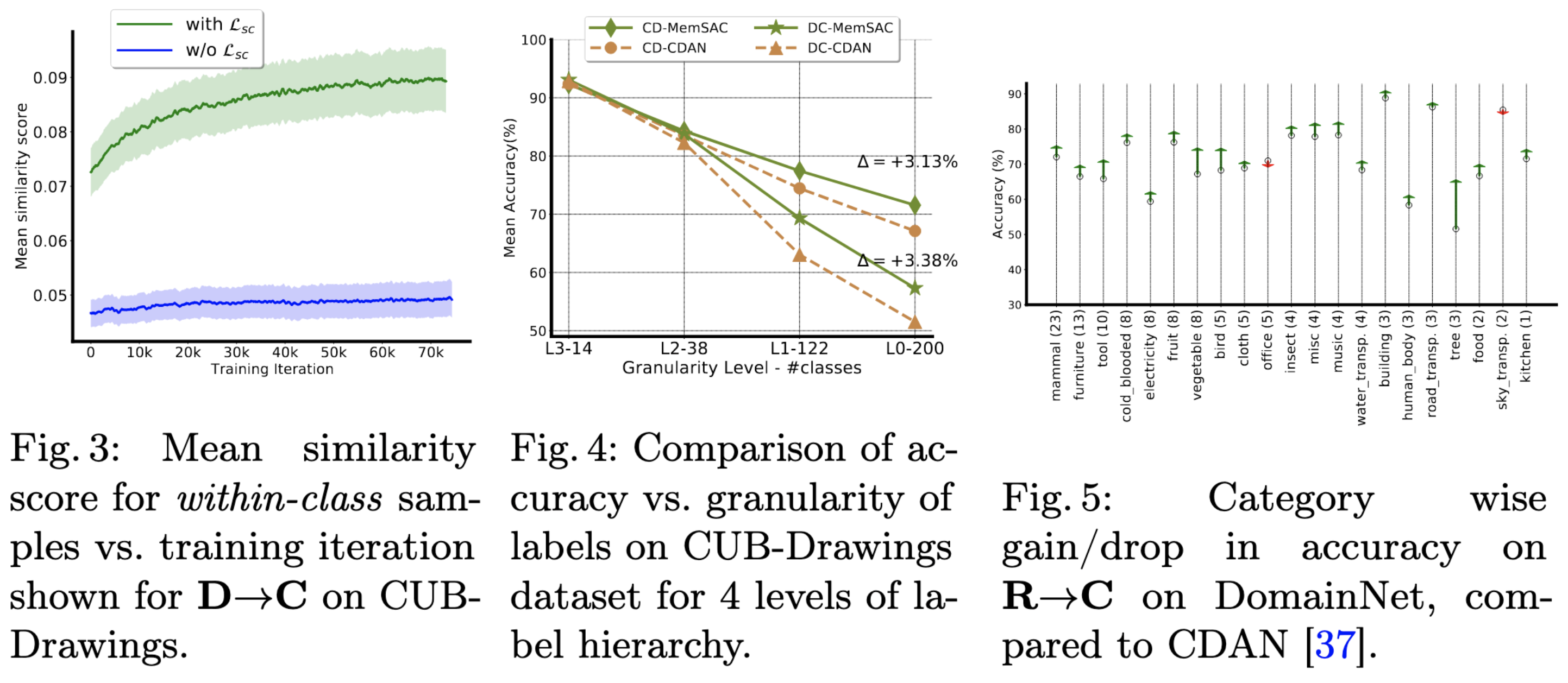
.

@inproceedings{kalluri2022memsac,
title={MemSAC: Memory Augmented Sample Consistency for Large Scale Domain Adaptation},
author={Kalluri, Tarun and Sharma, Astuti and Chandraker, Manmohan},
booktitle={Computer Vision--ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23--27, 2022, Proceedings, Part XXX},
pages={550--568},
year={2022},
organization={Springer}
}